As you may know, Sql server is one of the first database management systems for both operation and analytical purposes in data warehouses. As time goes by, as more and more cloud service providers start to appear, people seem to forget where they started when first learning about data.
I used to be a big fan of Azure, for the well-designed UI and no-code platforms (my apology for code-loving guys ![]() ). Despite the fact that most of our clients use Google solutions, let’s sit back and be prepare to learn a bit about Azure – Microsoft’s cloud computing service, in case we encounter any projects with Azure ecosystem in the future.
). Despite the fact that most of our clients use Google solutions, let’s sit back and be prepare to learn a bit about Azure – Microsoft’s cloud computing service, in case we encounter any projects with Azure ecosystem in the future.
Like other cloud computing services, there are plenty of tools you can find in Azure, not only for data, but also for other purposes, from dept ops, app-service, DNS to Virtual Machine providers. However, in this article, let’s just talk about their two platforms for data — Azure Data Factory and Azure Synapse Analytics.
Azure Data Factory (ADF)
Azure Data Factory is Azure’s cloud ETL service for scale-out serverless data integration and data transformation. It offers a code-free UI for intuitive authoring and single-pane-of-glass monitoring and management.
This is my favorite platform, due to the diversity of sources, sink and transformation it provides. Data Factory are also sufficient in transforming NoSQL data, connecting to private network/on premises data, complex transformation and data extraction purposes.

This tool works perfectly well with SQL Server Integration Services (SSIS), in migrating SSIS package to cloud, or run it locally. A company which is considering to move their data from on premises SQL server to cloud, can use Data factory as a replacement for their local SSIS.
Also, the capability of parsing json, digging into keys nested in several objects, apply transformation and loading data to sink are powerful weapon you will have when using ADF. For project which mainly use NoSql databases (such as MongoDB, Apache Cassandra, Redis, Google Cloud Bigtable or Amazon DynamoDB), Azure Data Factory is highly recommended to use.

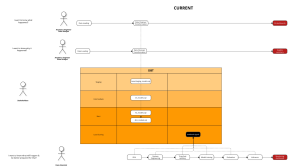
Above DAG is one of the complex transformations I used to conduct on ADF. The dataflow helps parse 600 nested keys, unpivot them and load the final data to snowflake.
Perhaps the common disadvantage of web-browser platforms is it can get really slow (or even crash) if the transformations are too complicated, data is too large, or event when pipelines take ages to run. In the above transformation, my web-browser crashed several times until it could successfully run and deploy.
ADF supports some data sources hosted outside of Azure, but it’s designed first and foremost for building integration pipelines that connect to Azure or other Microsoft resource types. This is a downside if you have a multi-cloud strategy that runs most of your workloads outside of Azure.
Read more about ADF in this
Azure Synapse (AS)
Azure Synapse Analytics is a limitless analytics service that brings together data integration, enterprise data warehousing, and big data analytics.
Released in 2019, Azure Synapse is one of the newest SQL platforms. It uses T-SQL to query data, similar to SQL server, but on cloud and much easier to use.
Different to Bigquery, Snowflake, or RedShift, there’re no data stored in Synapse. The platform is purely for querying and retrieving data, from different sources and warehouse. You can think of it as a substitution for local SQL Server Management Studio — first released in 2005.
AS allows you to query from different sources, event outside Azure platforms, with specification of url path, file format as below:
-- This is auto-generated code
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https:company1//c.dfs.core.windows.net/companyfile/company1/parquet/sessions/**',
FORMAT = 'PARQUET'
) AS [result]
There are 2 ways of using this SQL platform.

The first approach is to create a dedicated SQL cloud database for your data, then use AS to query data. Under this way, data is stored permanently in database and you will be charged for storage and computing cost like other data warehouse platforms. The performance is based on DWU (Data Warehouse Units) that we select when we create the resource. Minimum DWU is 100 and there will be one compute node for that. We can select to double our DWU to 200 which will give us two compute nodes and double the performance from single node.
The second approach is to use serverless SQL pool. A default endpoint for this service is provided within every Azure Synapse workspace, so you can start querying data as soon as the workspace is created. Under this approach, there is no charge for resources reserved, you are only being charged for the data processed by queries you run, hence this model is a true pay-per-use model. Sound like a good deal, however, the trade-off is coding practice for serverless SQL pool can be complicated comparing for first-time users. Also, due to the fact the data is not stored in normal SQL database, you need to configure a pipeline to for DDL, instead of simply typing alter/create or replace, which consumes quite a bit of effort.

Also, due to its complexity, you cannot connect serverless SQL pools to dbt ![]()
Because Azure Synapse uses Azure SQL Database, it’s limited to one physical database, so you must rely on using schemas separate your staging and DW tables. There are also T-SQL limitations, such as MERGE for ELT-based UPSERTs is not yet supported. So, don’t assume that you can seamlessly migrate your on-prem SQL Server to Synapse. Also, don’t assume that your SQL Server knowledge will suffice. Prepare to seriously study Azure Synapse!
For example, sql code to create procedure will take time to familiarize with for first-time users.
Create or alter Procedure create_fct_user_activities
@table varchar (200) = 'fct_user_activities'
as
Begin
Declare @table1 varchar (200) = @table ;
Begin
Declare @drop nvarchar (max) = 'Drop external table '+@table1+''
EXEC sp_executesql @tsql = @drop
end
Begin
Declare @Create nvarchar (max)=
'Create external table '+@table1+'
WITH (
LOCATION = ''Application/dim_tables/'+@table1+''',
DATA_SOURCE = [data_dfs_core_windows_net],
FILE_FORMAT = [SynapseParquetFormat]
)
as
WITH
remove_null AS
(SELECT
a.*,
b.name as user_names,
b.company_id
FROM stg_sessions a
left join stg_users b
on a.user_permission_id = b.id
where user_permission_id IS NOT NULL
and year(a.created_date) >= 2022 and month(a.created_date) >1),
FINAL AS
(SELECT a.id,
a.created_date,
ended_date,
session_id,
workflow,
reference_id,
user_permission_id,
user_names,
company_id
FROM remove_null a
LEFT JOIN dim_company b ON a.company_id = b.id
)
select * from final
';
print @Create
EXEC sp_executesql @tsql = @Create
End
end
Read more about AS in this

- Azure data service platforms overview - November 5, 2022
- How to migrate dashboards from Tableau to dbt and Looker - September 7, 2022