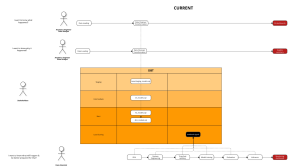
With the rise of the Modern Data Stack, more and more people use dbt as the main tool for data transformations, aka data modeling. The folks at Fishtown create an amazing dbt Cloud offering suitable for smaller/simpler data teams. With dbt Cloud, any Analyst, seasoned or fresh, can easily start modeling and deploying data transformations pipelines to production.
However, if teams want a bit (or a lot) more customizations when deploying dbt models to production, they often have to implement it themselves. For example, if I want to do a dbt run every time there is a push to production, I cannot do that yet with dbt cloud. Similarly, if I want to lint my code with sqlfluff or run custom data checks with great_expectations, I am out of luck with dbt Cloud also.
What not to do
There are many ways to deploy dbt to production. Not all of them are good ways, though. Here are some not so good ways to do that:
Spinning up a compute instance?
A common approach is to spin up a compute instance and install the required packages. From here, people can run a cron job to do a git pull and dbt run on a schedule.
This is a classic overkill solution as dbt does not require a lot of resources to run. What dbt actually does is compile queries and send them to your data warehouse and await responses. If you want notifications for pipeline failure, you would often have to implement that yourselves too.
Moreover, most of the time, your instance will be sitting idle burning your monies since dbt will mostly be run for a couple of minutes to less than an hour a day anyway. There is no easy solution to implement CI/CD with this option neither.
OK, what about Airflow?
Well, it depends. If you don’t have Airflow running in productions already, you will probably not need it now. There are more simple/elegant solutions than this (GitHub Actions, GitLab CI). Also, this approach shares many disadvantages with using a compute instance, such as waste of resources and no easy way for CI/CD.
However, if your team uses Airflow or any other pipeline orchestrator out there, you can consider writing a dag to trigger dbt. Especially when you have different ingests at different intervals that need to trigger dbt or subsequent tasks afterward.
Deploying dbt in Production
Since dbt is always deployed using git, utilizing the CI/CD function of your git provider of choice is the best way to deploy dbt to production. You will gain a lot of flexibility with this approach.
Let’s take a look at how we can do that using GitHub Actions. The free quota is likely sufficient for you and your team, but if you have a large team or use GitHub Actions in other projects, you may hit the quota and need to upgrade.
Setup a dbt profile for GitHub Actions
Create a profiles.ymlfile at the root of your repository. Every time it runs, dbt will look for this file to read in settings.

If you use a different data warehouse than BigQuery, be sure to change the parameters accordingly. The environment variables can be defined as repository secrets in GitHub followingNotice that we have two different targets for our different environments: dev and prod. Running dbt run will default to dev (configured by the target key). If you want to run on the prod target, use dbt run --target prod.
Setup credentials
Before running anything using GitHub Actions, you need a credential for the service to authenticate access to your data warehouse. It is highly recommended that you create a dedicated credential for this instead of using your own account. That way, if you lose access to your account for some reason, the service will still run.
Be sure to grant the necessary permissions to your account too. In our example above, we use BigQuery, which means creating a github-action service account, granting it read access to data sources and writing access to data destinations.
If you use a file credential (service account instead of user name and password), you can still use GitHub secret as above and use a echo command to write that to a file.
dbt run on a schedule
You can use the template below to add a GitHub Actions job that runs on a cron schedule. Add this file to the .github/workflows/ folder in your repo. If the folders do not exist, create them.

This script will execute the necessary steps for most dbt workflows. If you have another special command like the snapshot command, you can add another step in.
This workflow is triggered using a cron schedule. The configured schedule above means run the workflow every day at 5 AM and 5 PM UTC. All times are in UTC, so you may want to convert the schedule to your local time.
That’s it, the job will be triggered twice a day every day, and you will be notified if the job failed.
dbt run on merge
A common workflow of many development teams is to create pull requests every time there is a change to the code base. A simple modification to the yml file above will achieve this.
push:
branches:
- mainDepends on the desired behavior, you can create a new workflow for this or merge it with the one above. A common use case for separating the two is to run only models that change upon merge to main. This can be achieved using the dbt slim CI feature and is a topic for another post.
Testing with a pull request
The workflow script for this event is very much similar to the ones above. One main difference is that this workflow will run on a development environment instead of a production environment. This ensures that any changes are verified, reviewed, and tested before deploying to the production environment.

You can see that we don’t need to specify a target because dev is the default target in our profiles.yml file. Every time there is a pull request to main, this workflow will run.
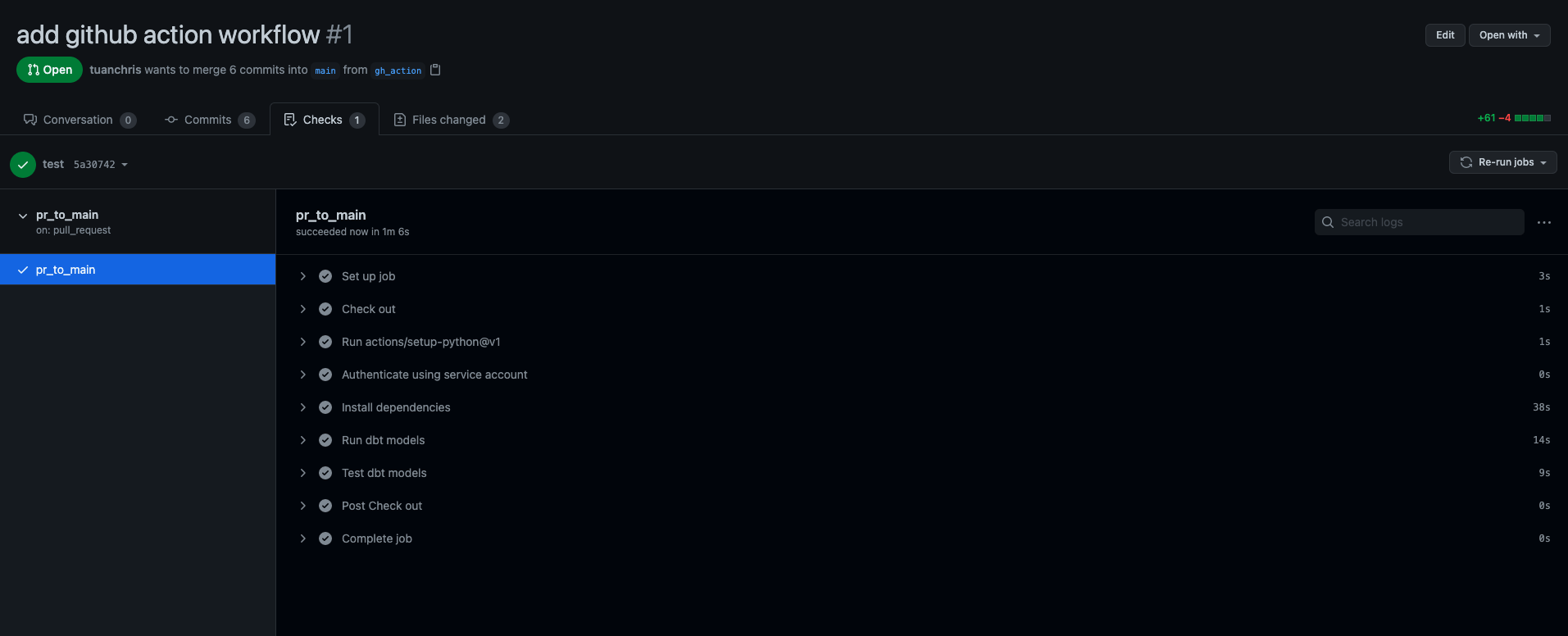
On smaller models, GitHub Actions takes only 1 minute to finish everything. Not bad! If you have too many models or too much data, running everything every time does not make sense, though. I will address this in a later post.
Linting with sqlfluff
One of the things that I missed when writing SQL models is a good linter. It is important to have agreed-upon conventions to follow so your codebase will not grow out of control over time. Linting with dbt is a bit more tricky, though, because it is actually Jinja SQL with a different dialect.
A good one that we finally have been able to adopt is sqlfluff. It is not 100% bug-free, though, so beware. You will only need to run the linter for the pull request to main workflow. To do that, add the following steps to your workflow:

I’m also sharing our sqlfluff configs here for your reference.
Conclusion
That’s all for this week. We have covered:
- Setting up dbt and credentials for GitHub Actions
- Running dbt on a cron schedule
- Running dbt on a pull request to main
- Linting dbt code with sqlfluff

- How to Deploy dbt to Production using GitHub Actions - August 23, 2021
- 6 Steps To Deal With Daily Email Hurdle - August 10, 2021
- 8 Tips to Greatly Enhance Your VSCode Productivity - August 10, 2021