Incremental Strategies & When to Use Them
Incremental materialization is an advanced and powerful feature of dbt; however, you don’t need to use it in every single model of your project. Understanding when and how to leverage incremental materialization can be a game-changer for your data workflows.
In this blog post, I’ll delve into the benefits and trade-offs of incremental and full refresh approaches and guide you through the decision-making process, helping you maximize the efficiency of your data models.
1.1. Incremental vs. Full Refresh
Using the full refresh strategy, dbt will discard the current destination table and create a new one from the whole source transformed data. While using incremental models, you can transform and insert into your tables only recent data.
When choosing between Incremental and Full Refresh, we need to consider the following factors:
The tradeoff between complexity and processing cost/time
Full Refresh has low complexity, you don’t need to worry about any incremental rules and configurations, but it can spend more time and cost more money rebuilding the whole table. However, the transformations are not very costly if the table is not large (a few million rows or less). There is no problem in sticking to full refresh.
Incremental is helpful if data tables have millions, or even billions, of rows or the transformations on the data are computationally expensive (that is, take a long time to execute), for example, complex Regex functions, or UDFs are being used to transform data.
The data change frequency
If the data in the model doesn’t change that much, you don’t take much advantage of the incremental strategies, you can make periodic full refreshes.
But suppose the historical data of the model changes a lot, the incremental strategy will not help to capture the change because it only worries about recent data. In that case, a full refresh could be a better option.
1.2. Incremental Strategies
1.2.1. Append
The append strategy is very straightforward; it just inserts the selected records into the destination table. It can’t update or delete records, just insert. You can only use this strategy if duplicates aren’t your problem.

1.2.1. Merge & Merge with clustered
The merge strategy solves the duplicated records problem. If the unique key already exists in the destination table, the merge will update the record. And if the records don’t exist, merge will insert them.


1.2.3. Delete+insert
The delete+insert strategy is very similar to merge, but instead of updating existing records and inserting new records, it deletes existing records and inserts both new and existing records.

1.2.4. Insert+overwrite (with partitioned)
This strategy solves the problem of full scan. The solution used by insert overwrite is to work with partitions. For insert overwrite to perform the partition can be of the following types: date, datetime, timestamp, int64. But if the timestamp is skewed, Insert+overwrite is not an ideal solution.
The insert overwrite strategy deletes the selected partitions from the current destination table and inserts the selected transformed partitions into it.

However, it can generate duplicates if you do not set it right. A periodic full refresh solves this problem, but if you can’t wait for the entire refresh to run, you should use another column or consider using the merge strategy.
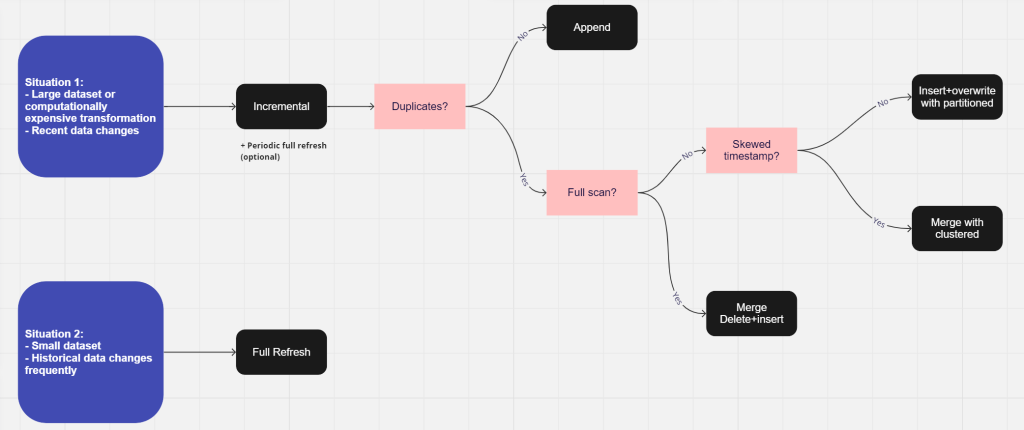
1.3. Decision Tree: Choosing the Right Strategy
Based on the pros and cons mentioned above and cons of each strategy, I make the decision tree to help you decide the most optimal materialization.


- Building a dbt project from scratch - January 15, 2024
- dbt Incremental part 2: Implementing & Testing - January 5, 2024
- Inventory Management & Demand Forecasting for E-commerce Sellers + Tutorial - December 18, 2023